Travailler depuis les sources : guide pas-à-pas
Ce wiki constitue une manière d’illustrer ma démarche de conception, de création et d’apprentissage au sein des pratiques numériques, à travers des processus d’auto-apprentissage, de partage et de redirections.
Ainsi, ce guide vous explique comment crée un fork de mon projet de mémoire afin de pouvoir étudier son fonctionnement, soumettre des modifications et proposer une version alternative de ce dernier.
Emprunté au monde de la piraterie, un fork désigne une bifurcation au sein d’un projet afin de lui donner une nouvelle direction, de nouvelles entités indépendantes et autonomes sont créées mais conservent des similitudes avec le projet-mère.
AVERTISSEMENT : Le tutoriel qui suit est amené à utiliser un jargon informatique qui n’est pas directement référencé dans le lexique de mon mémoire.
La raison est que je souhaite m’adresser ici aux néophytes, dans le vocabulaire le plus accessible possible, en explicitant chaque étape nécessaire à l’exécution des opérations décrites plus bas, soit par une mise au point soit par une redirection vers une ressource annexe.
Je ne prétends pas réaliser un tutoriel de vulgarisation informatique, je n’aurais ni le recul ni le niveau de compétence nécessaire pour parvenir à une parfaite synthèse.
Je cherche avant tout à poser des briques à peu près correcte pour pouvoir faire en sorte que des points spécifiques puissent être discutés, reformulés et corrigés.
Les images présentées dans cette page de tutoriel sont uniquement à but illustratif et, pour des raisons de multiplicités de versions et type de système, ne sont pas représentatifs de l’aspect visuel final de votre projet et dépendances.
Sommaire :
Avant toutes choses …
I. Anatomie du dépôt
_bibliographie
- bibliographie.bib
_includes
- footer.html
- head.html
- header.html
_layouts
- cover.html
- default.html
- defaultn.html
- microtypo.html
- print.html
_memoire
- replace-regex.rb
_sass
- _code.scss
- _layout.scss
- _mixins.scss
- _normalize.scss
- _pygments.scss
- _tables.scss
- _typography.scss
_wiki
- screenshots
css
- main.scss
- print.scss
fonts
- font
images
- image
scripts
- lunr.min.js
- orderedList.js
- search.js
telechargements
- telechargement
Autres
- _config.yml
- .gitignore
- 404.md
- Gemfile
- Gemfile.lock
- impression.md
- index.md
- LICENSE
- README.md
- recherche.html
- robot.txt
- search.html
II. Chaîne d’édition Web
III. Chaîne d’édition Papier
Avant toutes choses …
Bravo ! Si vous êtes sur cette page de wiki, c’est que vous avez réussi à faire une copie du dépôt en local, auquel cas je vous invite à vous diriger à la page consacrée à Windows, OSX ou Linux.
Nous allons maintenant voir comment travailler sur le dépôt du mémoire, la première chose à savoir est qu’un programme est un ensemble d’instruction reposant sur des chaînes de commandes comprenant entre autre des fonctions et des descriptions.
Cela signifie que l’on va avant tout s’occuper d’éditer les fichiers qui vont nous permettre de rédiger le contenu de notre mémoire, les feuilles de styles qui gèrent l’aspect visuel, d’autre les dépendances, …
Chaque module, que l’on va décrire en premier lieu, est assigné à une ou plusieurs suites de tâches, description, … il est donc essentiel de savoir à quoi ces derniers servent ; puisqu’il participent à créer un chaîne de conception et d’édition qui feront l’objet d’une description en deuxième et troisième partie.
I. Anatomie du dépôt
_bibliographie
Ce fichier contient l’ensemble des références bibliographiques enregistrées au format BibTex utilisées pour les citations dans les textes. Pour plus de commodités, il est possible d’utiliser un logiciel comme Zotero afin de générer votre bibliographie au fur et à mesure.
Pour émettre une citation dans le texte rédactionnel, il faut insérer la formule : {& cite 'nom_de_votre_réference' &} derrière votre texte. Il est possible de modifier les informations de votre référence dans le fichier .bib référencé.
L’affichage de la bibliographie se fait avec la formule : {& bibliography --query @'type_article' &} dans un fichier consacré à la rédaction des pages d’articles.
_includes
Ce dossier contient l’ossature des pages HTML générées par Jekyll durant le processus de compilation final du site.
Ce fichier HTML permet d’intégrer dans la génération de page web le code HTML correspondant aux informations que l’on trouve en bas de la page de votre site, une section correspond aux hyperliens de référence tandis l’autre est un script permettant de créer un menu vertical déroulant du site.
Ce fichier HTML correspond aux information qui seront lues en premier par votre navigateur, il correspond à la carte d’identité de votre site web et ce qui lui permet de pouvoir être référencé par les moteurs de recherche, dans le cas où le SEO serait important dans la diffusion de votre projet.
Ce fichier HTML correspond à l’organisation du menu vertical déroulant constituant l’en-tête du site web car c’est à partir de ce dernier auquel on accède à l’ensemble des parties du site.
_layouts
Ce dossier contient les feuilles sémantiques contenant les fichiers _includes précédents et organisant un ensemble de patrons destinées à être utilisés spécifiquement selon le type de page web que l’on veut faire.
Ce fichier HTML correspond à une feuille de style attribuant la structure sémantique de la page de couverture du site web.
Ce fichier HTML correspond à une feuille de style attribuant la structure sémantique des pages rédactionnelles du site web.
Ce fichier HTML correspond à une feuille de style attribuant la structure sémantique des pages rédactionnelles du site web. A noter que cette variation supprime la numérotation des paragraphes.
Une redirection d’appel de fonction d’un composant de fichier Gemfile permettant d’intégrer les ponctuations française.
Ce fichier HTML correspond à une feuille de style attribuant la structure sémantique de la page print-to-html dont le processus sera décrit en détail dans la partie 3
_memoire
Ce dossier, qui est parmi les plus important de se dépôt, est dédié à la rédaction en lui-même du contenu de ce mémoire. Le langage Markdown est utilisé car il permet de rédiger en HTML de manière simplifiée sans avoir à connaître l’ensemble des balises.
Ce fichier MarkDown contient la partie rédactionnelle des pages du site web.
Ce fichier Markdown contient un appel de fonction en YAML permettant d’organiser les liaisons entre les différentes pages du site web.
_plugins
Ce greffon permet entre autre de remplacer les chaînes de caractère entre parenthèse `` entre autre mais permet surtout d’intégrer les fonctions Liquid au sein d’un générateur Jekyll.
_sass
Ce dossier contient les fichier de composition de feuille de style écrits en SASS
Ce fichier SCSS permet de modifier le style visuel des inserts de code exemple_de_code sur les pages du site web.
Ce fichier SCSS permet de modifier le style visuel des feuilles de style sémantique sur les pages du site web.
Ce fichier SCSS permet de modifier le style visuel des appels de fonction WebKit présentes sur certains navigateurs.
Ce fichier SCSS permet d’ajuster les appels de fonction WebKit sur les navigateurs et systèmes embarqués susnommés.
Ce fichier SCSS permet de référencer l’ensemble des paramètres liés à la mise en couleur du texte.
Ce fichier SCSS permet d’ajuster le style visuel de l’arrière plan de la page web.
Ce fichier SCSS permet de référencer l’ensemble des paramètres liés à la typographie
_wiki
Ce dossier contient l’ensemble des images utilisées dans les wikis du projet et qui ne sont pas référencées sur le web.
css
Ce fichier SCSS constitue la feuille de style utilisée sur la version web du mémoire et qui inclus l’ensemble des fichiers du dossier _sass
Ce fichier SCSS constitue la feuille de style utilisée sur la version PDF du mémoire, généré avec l’outil PagedJS dont l’usage sera expliqué dans la partie 3 du wiki.
fonts
Ce dossier contient l’ensemble des fontes et de leurs variations utilisées pour le mémoire au format .woff.
images
Ce dossier contient l’ensemble des images utilisées dans le mémoire et qui ne sont pas référencées sur le web.
scripts
Ce script Javascript permet d’extraire une chaîne de caractère au sein des paragraphes et des en-têtes des fichiers HTML. Il s’agit d’un élément du greffon jekyll-lunr-js-search
Ce script Javascript permet d’utiliser PagedJS et inclus également des routines de préprocesseur lors de l’affichage par le navigateur web
Ce script Javascript permet de gérer les appels de recherches et de réponses via le navigateur. Il s’agit d’un élément du greffon jekyll-lunr-js-search
telechargements
Ce dossier contient le fichier PDF généré avec PagedJS, dont l’usage sera expliqué dans la partie 3 du wiki.
Autres
Ceci est le fichier de configuration écrit en YAML qui permet de faire appel aux fonctions Liquid afin de remplacer les `` par les éléments présent dans ce fichier-ci.
Ce fichier permet de ne pas ajouter dans le suivi de version de -Git_ certains dossiers ou fichiers et également de ne pas les inclure dans la génération du site avec Jekyll.
Ce fichier MarkDown permet de rédiger la page d’Erreur 404 qui sera ajoutée durant la génération du site avec Jekyll.
Ce fichier Ruby contient l’ensemble des sources de greffons Ruby appelé gem qui permettent de générer notre serveur Ruby et entre autre utiliser Jekyll.
Ce fichier Ruby contient l’ensemble des extensions des sources de greffons Ruby appelé gem qui permettent de générer notre serveur Ruby et entre autre utiliser Jekyll.
Ce fichier MarkDown permet de rédiger impression.html qui sera ajoutée durant la génération du site avec Jekyll et qui utiise la feuille sémantique print.html dans _includes
Ce fichier MarkDown permet de rédiger index.html qui sera ajoutée durant la génération du site avec Jekyll et qui utiise la feuille sémantique cover.html dans _includes
Ce fichier texte est une reproduction de la licence en vigueur sur le projet.
Pour les contenus du site, licence CC BY-NC-SA : Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions.
Ce fichier MarkDown contient les informations importantes concernant le dépôt en général et la démarche de conception qui y est recherchée.
Ce fichier permet de créer une page de navigation pour entrer et exécuter une recherche.
Négligeable mais peut-être permet-il de filtrer le référencement ?
Ce fichier permet de créer une page de navigation pour faire défiler des recherche.
II. Chaîne d’édition Web
Pour comprendre les raisons de mettre en place une chaîne d’édition pour le web, il est important de savoir que la grande difficultés de publier un carnet de recherche en ligne est lié à différents facteurs, qu’ils soient humains, technique ou lié au contenu :
-
La personne derrière un travail de recherche en ligne doit s’assurer qu’elle est capable de comprendre et de se mettre à la place de l’ensemble des corps intermédiaires de l’écriture jusqu’à la publication de son travail en passant par la réception des retours de spécialistes pour appuyer ou contredire certains points nécessaires.
-
La personne intéressé doit également se former aux bases du Web, que ce soient les langages de programmation comme les solutions d’hébergement entre autre, ou trouver une personne capable, moyennant rémunération, de réaliser de A à Z la création et la maintenance d’un site web. Tout dépend du degré d’investissement que le chercheur est prêt à mettre, s’il désire tout créer seul ex nihilo, sous-traiter à un collaborateur ou collaboratrice ou bien utiliser un système de gestion de contenu prêt à l’emploi.
-
Enfin, et c’est le cœur-même du travail de recherche, s’assurer que ce que l’on énonce puisse être validé par des arguments, des expériences ou en tout cas des preuves vérifiables et accessibles via des sources sûres. Par conséquent, le contenu doit pouvoir être révisé par de multiples corrections au fur et à mesure.
Le cycle d’un travail de recherche s’accorde cependant moins facilement avec des manières de faire itératives ainsi que par des récits personnels, pourtant il faut noter que l’expérience subjective, bien qu’elle ne soit pas une finalité en tant que sujet dans la recherche, est aussi un élément important, qui permet entre autre de défricher les voies dans lesquelles on ne s’est pas encore égaré durant une errance.
Dans le cas de mon projet de mémoire, j’ai choisi de m’appuyer sur un environnement de travail utilisé par quelqu’un d’autre à la place d’un CMS de type Wordpress car il était nécessaire pour moi d’échapper au complexe de la boîte noire qui est mentionné dans ma recherche et également parce que le partage et la transmission d’une expérience sont des éléments important pour le développement de toute pratique numérique.
Un générateur de site statique va permettre de convertir un ensemble de fichier en page HTML statique que l’on va pouvoir uploader sans avoir besoin d’utiliser une base de donnée pour générer des fichiers à la volé. On peut définir différents type de fichiers de travail sur lesquelles on va pouvoir intervenir :
- Le balisage rédactionnel concerne le travail d’écriture du contenu, ce que le lecteur doit lire avant tout.
- Le balisage sémantique concerne la structuration et la relation du contenu avec les différentes typologies d’information possible
- Le balisage stylistique concerne la mise en forme du contenu afin de différencier et signifier les différentes informations.
- Le balisage applicatif concerne la couche dynamique d’exécution des scripts.
Avant de mettre en ligne votre projet web, il est important de vous poser les questions concernant vos souhaits, les moyens ou les compétences techniques que vous avez :
-
Un serveur web autogéré de type Apache ou NGINX n’est pas vraiment recommandé si vous n’êtes pas rompu à la création et à la gestion de serveurs persistant mais nous n’aurez pas besoin de louer du stockage chez un hébergeur.
-
Vous pouvez également réserver à l’année un nom de domaine ou DNS qui redirige l’adresse IP de votre serveur vers un domaine plus précis pour qu’il puisse être référencé par les moteurs de recherche. Vous pouvez comparer les offres présentes chez des hébergeurs comme OVH ou Infomaniak.
-
Vous pouvez également utiliser un CDN pour afficher les pages web présentes dans vos dépôts. De base gratuite, il est également possible d’avoir des propositions forfaitaires pour un stockage illimité et un streaming de contenu vidéo par exemple. Vous pouvez comparer les offres présentes chez des hébergeurs comme GitHub Pages ou Netlify.
La dernière solution correspond à un équilibre entre le coût financier (l’hébergement est gratuit dans notre cas) et la simplicité d’utilisation, car une fois le projet en ligne, toutes modifications dans le dépôt met automatiquement le site à jour.
Mais avant d’en arriver là, il faut héberger notre projet en créant un dépôt sur des sites de forges comme GitLab, GitHub ou Bitbucket. Il faudra ensuite lier le dépôt local du dossier de travail vers le dépôt distant en ajoutant un URL de connexion puis exécuter les commandes suivantes à l’aide du terminal Git Bash:
# pour initialiser le dépôt local
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 (master)
$ git init
# pour ajouter l'URL de connexion, vous serez amené à taper le mot de passe de votre identifiant de dépôt de forge pour synchroniser une fois pour toute votre dépôt local avec celui distant.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 (master)
$ git remote add origin git@'adresse_du_dépôt':'utilisateur_du_dépôt'/'nom_du_dépôt'.git
# pour ajouter toutes les modifications locales.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 (master)
$ git add .
# pour créer un nouveau commit du projet dans la base de donnée du répertoire HEAD du dossier .git c'est à dire une sauvegarde des modifications effectuées sur les fichiers à un instant T.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 (master)
$ git commit -m "modification"
# pour créer une nouvelle branche et y bifurquer afin de travailler sur des voies parallèles.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 (master)
$ git branch "'nom'" && git switch "'branch'"
# pour vérifier l'état du dépôt local.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 ('nom')
$ git status
# pour envoyer les fichiers du dépôt local vers le dépôt distant.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 ('nom')
$ git push origin 'nom_de_la_branche'
# pour récupérer en local les modifications effectuées sur le dépôt distant.
'SESSION'@'NOM_ORDI' MINGW64 ~/Documents/DNSEP_Report_EESI_2020 ('nom')
$ git pull origin 'nom_de_la_branche'
Il est parfois intéressant d’utiliser des exemples visuelles pour comprendre comment marche un système, ici Git expliqué avec des chats
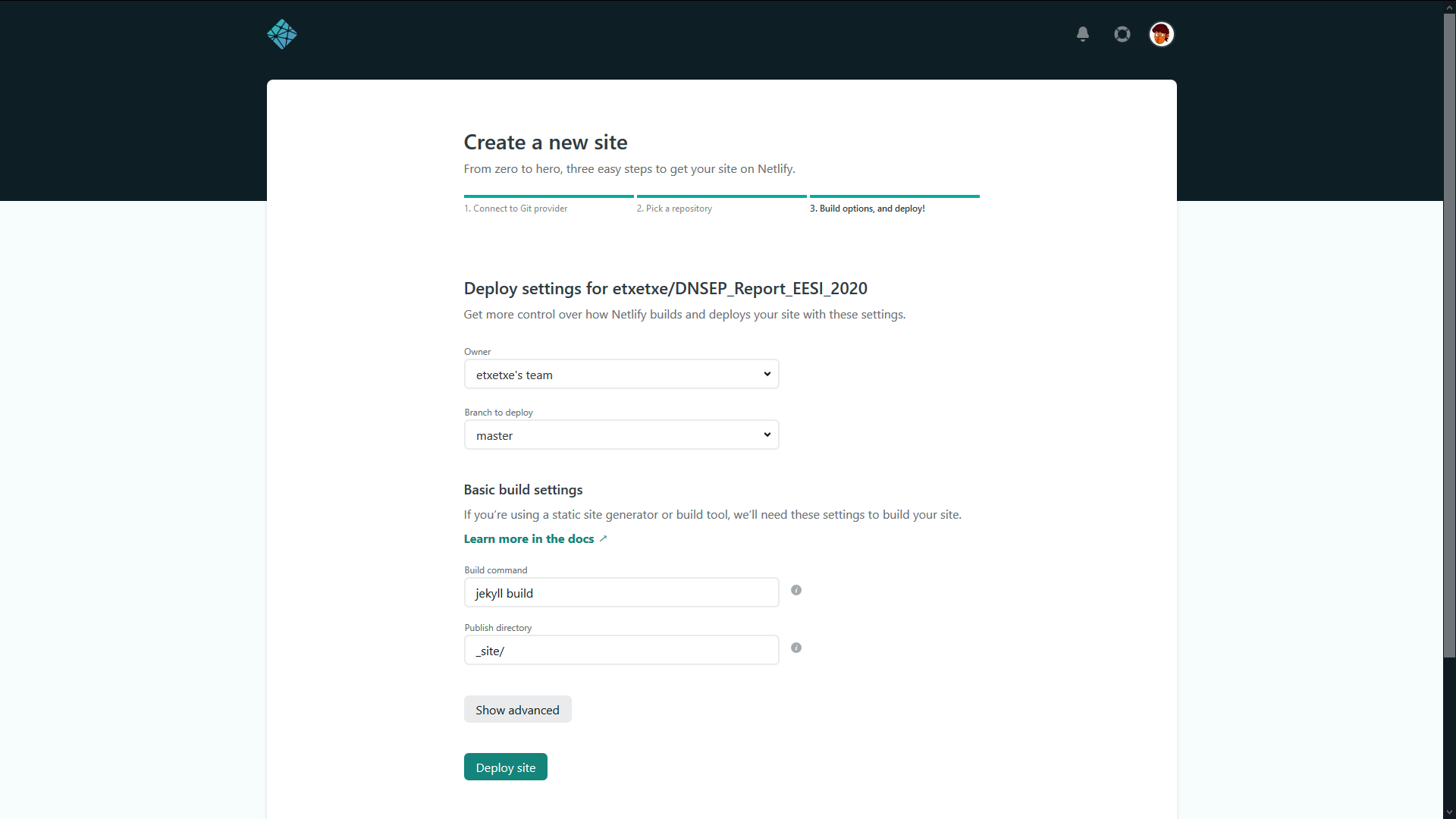
Après avoir créé un dépôt et commencé à travailler dessus, il est temps de mettre de site en ligne : la méthode va se concentrer sur le CDN Netlify, choisissez le dépôt de forge dans lequel vous travailler puis identifier vous pour le synchroniser avec le CDN.
Choisissez le dépôt ou se trouve le site à faire héberger pour ensuite accéder au menu de configuration du projet à déployer.
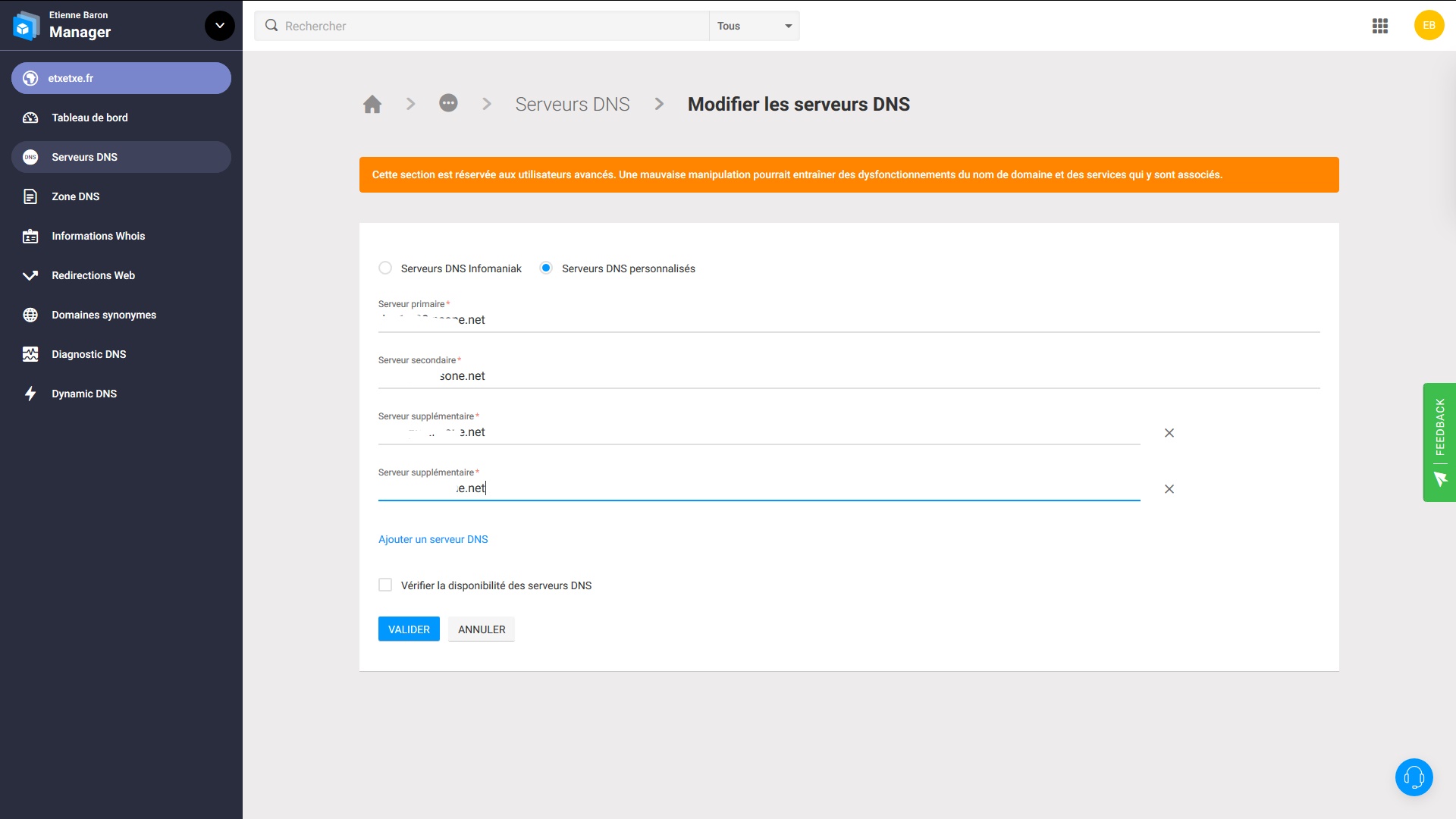
Vous pouvez également utiliser un nom de domaine personnalisé en récupérant les adresses de serveur dans les paramètres DNS de votre site hébergé et en remplaçant sur votre gestionnaire de DNS de votre hébergeur les adresses de serveur par celles personnalisées afin de faire une redirection de DNS
III. Chaîne d’édition Papier

